|
|

Prepared By: Arifah Munirah Bt Zulkafli (037221)
Supervised By: Dr Suhailan B. Dato' Safie Course: Bachelor of Computer Science Internet Computing (Hons)](Universiti Sultan Zainal Abidin Terengganu (UniSZA) Contact Number : +6019-9471092 Email : [email protected] |
ABSTRACT
Selection of student placement in Internship based on CGPA is no longer appropriate. Therefore, the Industry choose student based on their skill and expertise in a particular field to add more expert in Industry. The obvious problem here is, student skill has been determined based on their CGPA that are not reflected to student actual skill. So, CGPA is not suitable to group student according to a particular skill. Thus, this project may help student to be grouped based on their skill strength according to their course grade. The result can be used for better internship placement that are suitable based on their skills and interest. . In realizing this solution, K-Means Clustering technique will be used. K-Means Clustering are is an unsupervised learning algorithm that tries to cluster data based on their similarity. Score range student that are unsupervised will be grouped based on their similarity. The similarity result of students’ that has been distributed based on clustering may help university to distribute them in placement of Internship that is suitable with their interest and expertise.
INTRODUCTION
Internship component is a vital part of the university training program for students to gain the required skills for employment in pursuit of degree certification. However, some students faced problems to choose their internship placement because they did not know their strength and interest. Cumulative Grade Point Average (CGPA) is commonly used as indicator for academic achievement. Many higher learning institution set a minimum CGPA requirement set for student is 1.5. Whereas, for any graduated program, CGPA of 3.00 and above are considered as good achievement.
While in this case, grouping of students into different categories according to their achievement are not reliable and has become a complicated task. With traditional grouping of students based on their average scores, it is hard to acquire a view of the state of the students’ achievement. Emphasised are this Internship Recommendation System (IRS) Based on Student’s Course Achievement Using K-Means Clustering will be implemented to help students to overcome this problem. This system will analyse student course grade based on clustering analysis with K-Means Algorithm. Thus, students need to fill up their grade of course subject and they will be distributed in groups that are similarly based on K-Means Clustering Algorithm. Then, student will know their level of strength and interest. So that, they can apply for internship placement that are suitable for them, that has been recommended by the system.
While in this case, grouping of students into different categories according to their achievement are not reliable and has become a complicated task. With traditional grouping of students based on their average scores, it is hard to acquire a view of the state of the students’ achievement. Emphasised are this Internship Recommendation System (IRS) Based on Student’s Course Achievement Using K-Means Clustering will be implemented to help students to overcome this problem. This system will analyse student course grade based on clustering analysis with K-Means Algorithm. Thus, students need to fill up their grade of course subject and they will be distributed in groups that are similarly based on K-Means Clustering Algorithm. Then, student will know their level of strength and interest. So that, they can apply for internship placement that are suitable for them, that has been recommended by the system.
OBJECTIVES |
METHODOLOGY |

|
|
FRAMEWORK
K-MEANS CLUSTERING ALGORITHM
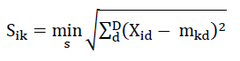
Clustering is the process of partitioning a group of data points into a small number of cluster. For instance, the mark of student can be clustered in categories (CGPA 3.5 and above as Dean list student). Of course this is a qualitative kind of partitioning. A quantitative approach would measure certain features of the student mark, say an average mark of student will be grouped together.
In this project, it will cluster student course achievement based on their similarities of attributes (i.e. criteria and alternative). This object will consists of two (2) attributes which are Subject A and Subject B marks. This algorithm will be developed in the lecturer module. Whereby, after student has been clustered based on their group achievement, lecturer will assign them with Internship Company that suit their strength and skill.
There are Three (3) main processes involved in the K-Means Clustering which are Initial Centroid selection, nearest cluster assignment and centroids update.
a) Initial Centroid Selection
Centroid (n) is assign to a cluster centre that is illustrate using the feature points for a group if the nearby assigned object. It also used as a reference point in assigning object into a cluster based on their nearest distance to the centroid. In the beginning of the assignment process, a number of K set of initial centroids need to be predetermined so that the object can be assigned accordingly. In basic K-Means, these initial centroids are randomly selected among objects.
b) Nearest cluster assignment
Clustering process begins by measuring each object distance on each centroid.
Where Sik is set of object in cluster-k, k=0 to K and d is a feature. The objects will be assigned to a cluster where they have the closest distance to the centroid. The distance measurement is using the Euclidean Means nearest object measurement.
c) Centroids Update
This is the last step where once the objects have been re-assigned, the centroid for each cluster needs to be re-calculated.
This step is to ensure that all objects that currently assigned to a cluster definitely belong to that cluster (i.e. nearest to its new assigned centroid) and far away from other cluster. If there is an object that turns out to be nearer to another centroid, then this object needs to be reassigned to the nearest cluster. Thus, iteratively, the whole process cycle starting from step (b) to (c) needs to be repeated until there are no nearest changes to the centroids in all clusters.
In this project, it will cluster student course achievement based on their similarities of attributes (i.e. criteria and alternative). This object will consists of two (2) attributes which are Subject A and Subject B marks. This algorithm will be developed in the lecturer module. Whereby, after student has been clustered based on their group achievement, lecturer will assign them with Internship Company that suit their strength and skill.
There are Three (3) main processes involved in the K-Means Clustering which are Initial Centroid selection, nearest cluster assignment and centroids update.
a) Initial Centroid Selection
Centroid (n) is assign to a cluster centre that is illustrate using the feature points for a group if the nearby assigned object. It also used as a reference point in assigning object into a cluster based on their nearest distance to the centroid. In the beginning of the assignment process, a number of K set of initial centroids need to be predetermined so that the object can be assigned accordingly. In basic K-Means, these initial centroids are randomly selected among objects.
b) Nearest cluster assignment
Clustering process begins by measuring each object distance on each centroid.
Where Sik is set of object in cluster-k, k=0 to K and d is a feature. The objects will be assigned to a cluster where they have the closest distance to the centroid. The distance measurement is using the Euclidean Means nearest object measurement.
c) Centroids Update
This is the last step where once the objects have been re-assigned, the centroid for each cluster needs to be re-calculated.
This step is to ensure that all objects that currently assigned to a cluster definitely belong to that cluster (i.e. nearest to its new assigned centroid) and far away from other cluster. If there is an object that turns out to be nearer to another centroid, then this object needs to be reassigned to the nearest cluster. Thus, iteratively, the whole process cycle starting from step (b) to (c) needs to be repeated until there are no nearest changes to the centroids in all clusters.
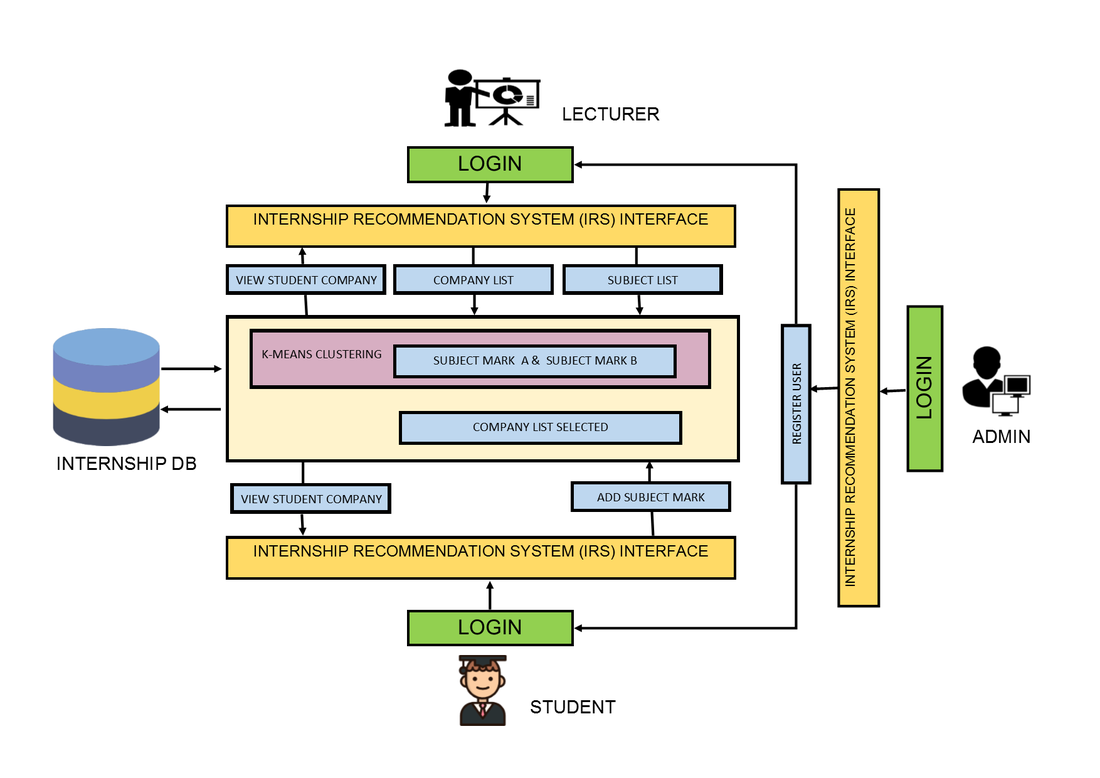
RESULT [ ADMIN PAGE]
"Admin will handle to manage user (student and lecturer) account registration"
RESULT [LECTURER PAGE]
"In this lecturer page have Clustering Module, where lecturer will be given a student cluster result based on student's subject mark. Then lecturer need to add student to the company based on the best cluster result that recommended by the system"
RESULT [STUDENT PAGE]
"In this page, student will be recommend an internship company that has been assign by lecturer based on their skill and strength"
CONCLUSION